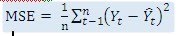Median polish adalah teknik statistik yang robust untuk menganalisis data cross-clasified untuk mengidentifikasi adanya suatu trends dan outliers dengan menghitung median dari kolom dan baris secara iteraksi dimana hasil akhirnya adalah sebuah model linear dari data tersebut. Hasil dari median polish adalah sebuah tabel residual yang mana data yang outliers seketika itu pula dapat dibedakan dan untuk median keseluruhan relativ tidak sensitiv dengan data-data yang outlier tersebut. Hal inilah yang menjadi alasan kenapa median polish diterima sebagai salah satu metode analisis data.(Rucker)
Metode yang pertama kali diperkenalkan oleh John Tukey ini lebih robust daripada ANOVA untuk menguji kesignifikanan faktor dalam model multi faktor. Median polish hampir sama dengan analisis varians tetapi median digunakan sebagai rata-rata sehingga lebih robust terhadap data-data yang bersifat outlier(“Data Analysis and Regression,”Mosteller and Tukey-Wesley, 1977(chapter 9)).
Ada 3 metode yang digunakan untuk menghitung nilai keberartian faktor yaitu one way, two way dan faktorial. Berikut ini prosedur masing-masing metode:
Metode One Way Median Polish
Metode one way adalah salah satu metode penghitungan median polish yang bertujuan menguji kesignifikanan faktor dari model multi faktor. Banyak faktor yang merupakan variabel independen harus diantara 1 sampai 5. Banyak level tidak sama dengan banyaknya faktor. Kombinasi dari faktor dan level adalah sebuah cell yang merupakan nilai dari kombinasi keduanya. Metode ini dapat dilakukan untuk observasi yang berimbang, model dari metode one way adalah :
Yij = μ +τi + eij (i = 1, 2, . . . , k; j = 1, 2, . . . , n) (1)
dimana :
Yij : respon pada perlakuan baris ke-i dan kolom ke-j
μ : rata-rata keseluruhan
τi : efek tiap blok
eij : random error
dalam salah satu jurnal iteraksi untuk metode one way median polish normalnya dilakukan sebanyak 2-3 kali atau untuk lebih tepatnya dilakukan sampai nilai rasio SUM of residual dari step sebelumnya dan sesudahnya kurang dari nilai cut-off-nya
Metode Two Way Median Polish
Dalam median polish two way elemen y(i,j) merupakan nilai kesesuaian dari tabel metode two way dimana i sebagai indek baris dan j sebagai indeks kolom. Setiap y(i,j) menjelaskan terminology dari sebuah model additive yang terdiri dari tiga komponen yaitu: nilai efek umum(common), Et, yang merupakan ringkasan dari semua level respon secara umum;nilai efek baris, Er(i), merupakan nilai dari perubahan respon dalam baris; nilai efek kolom, Ec(j), merupakan nilai dari perubahan respon dalam kolom. Secara matematis model dari median polish adalah sebagai berikut :
y(i,j) = Et + Er(i) + Ec(j) + R(i,j) (2)
dimana R(i,j) adalah nilai residual dari respon atau nilai yang tidak dijelaskan oleh model. (Rucker).
Metode menghitung adanya pengaruh dari efek baris dan kolom. Tujuan lain dari metode ini adalah melakukan perbandingan mean (fix) untuk kencenderungan (analisis regresi) dan melakukan perbandingan varians. Langkah-langkah dari metode ini adalah mencari median baris kemudian mengurangkan nilai data pada baris ke-i dengan median baris ke-i tersebut, selanjutnya mencari nilai median dari kolom pada kolom ke-j. kemudian mengurangkan tiap nilai di kolom ke-j tersebut dengan nilai mediannya. Iterasi ini diulangi sebanyak 2 kali. Untuk lebih jelasnya dapat dilihat dalam gambar 1 mengenai interaksi metode two way yang didapat dari buku A-B-C of EDA pada halaman 226 bab 8.

Gambar 1. Iteraksi Two Way Median Polish
gambar 1 menunjukkan bagaimana iteraksi pada metode median polish two dimana melakukan 4 kali iteraksi untuk mendapatkan nilai median kolom dan baris serta nilai common.
dalam penulisan ini masih ada yang kurang,mohon diteliti...